Why Third-Party Attribution Is Breaking and What First-Party Data Actually Requires
The collapse of third-party cookie-based attribution has been predicted for years, but the reality is messier than the predictions suggested. It's not a clean cutover — it's a slow degradation where numbers stay populated but become progressively less trustworthy. Campaigns that look stable in the dashboard are quietly losing signal. Attribution gaps are growing, but they're growing in ways that don't trigger obvious alarms.
The response most teams reach for — tightening UTM discipline, adding more pixels, switching analytics platforms — addresses symptoms rather than the structural problem. The structural problem is that attribution systems built on third-party identifiers, cross-site cookies, and platform-managed IDs have an expiration date. That date is approaching faster than most organizations have planned for.
First-party data is the only durable foundation for attribution. But "first-party data" is used loosely enough that it's worth being precise about what a first-party attribution pipeline actually requires — technically and architecturally — before talking about how to build one.
What First-Party Attribution Data Actually Means
The common definition — "data we collected ourselves" — is insufficient. An analytics platform can assign an identifier to your users under your domain while giving you no ability to read, reconcile, or restore that identifier when it breaks. The data is technically yours, but the identity infrastructure belongs to the platform.
First-party attribution requires three specific properties: you generate the identifiers, you control the persistence layer, and you can reconstruct the identity graph without depending on a third party's system to remain consistent. When any of these three properties is missing, you have a dependency that will eventually fail — and when it does, historical data becomes irreconcilable.
Short links are a critical entry point in this infrastructure. When a user clicks a short link, your server handles the request before any third-party system sees it. That millisecond of control is when identifiers can be generated, existing identifiers can be associated, and the first-party record of the interaction can be created. If that moment passes without server-side capture, the opportunity to establish first-party identity at the top of the funnel is gone.
The Core Architecture of a First-Party Attribution Pipeline
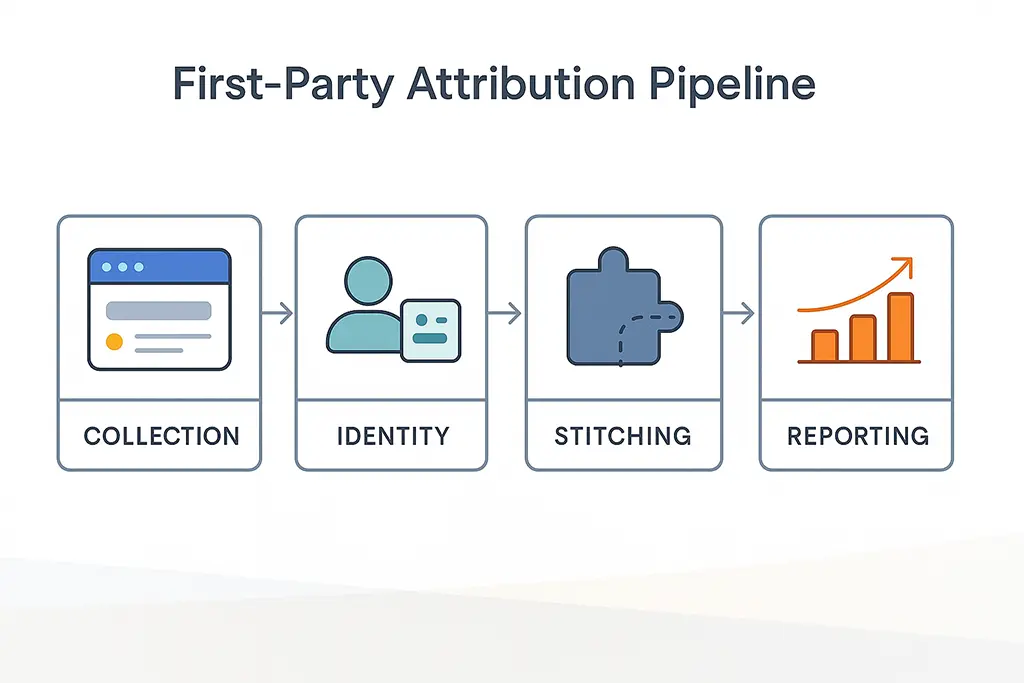
A first-party attribution pipeline is a set of design decisions, not a product category. The components need to work together as a system, and the decisions made at each layer constrain what's possible downstream. Working through each component before touching implementation is worth the time.
Entry Point Control: The Short Link as Attribution Anchor
Every attribution journey has an entry point. In campaigns using short links across social platforms, email, QR codes, and messaging apps, that entry point is where your server handles the initial request. This is the highest-value moment in the attribution chain because it's the only moment where you have full context: the incoming URL, UTM parameters, referrer header, IP subnet (for probabilistic device matching), and timing.
In a Spring Boot redirect handler, capturing this data before issuing the redirect is straightforward but requires explicit implementation — it doesn't happen automatically:
@GetMapping("/{code}")
public ResponseEntity<Void> redirect(
@PathVariable String code,
HttpServletRequest request,
HttpServletResponse response) {
ShortUrl shortUrl = urlService.resolve(code);
if (shortUrl == null) {
return ResponseEntity.notFound().build();
}
// Generate or retrieve first-party click ID before redirect
String clickId = generateClickId(); // e.g., UUID or snowflake ID
String existingUserId = extractExistingUserId(request); // from first-party cookie
// Capture full attribution context server-side before any redirect
ClickEvent event = ClickEvent.builder()
.clickId(clickId)
.shortCode(code)
.userId(existingUserId)
.utmSource(request.getParameter("utm_source"))
.utmMedium(request.getParameter("utm_medium"))
.utmCampaign(request.getParameter("utm_campaign"))
.utmContent(request.getParameter("utm_content"))
.utmTerm(request.getParameter("utm_term"))
.referrer(request.getHeader("Referer"))
.userAgent(request.getHeader("User-Agent"))
.ipSubnet(maskIp(request.getRemoteAddr())) // store subnet, not full IP
.timestamp(Instant.now())
.destinationUrl(shortUrl.getDestination())
.build();
// Persist synchronously or async depending on latency requirements
clickEventRepository.saveAsync(event);
// Set first-party cookie with click ID for downstream correlation
Cookie clickCookie = new Cookie("_vvd_cid", clickId);
clickCookie.setMaxAge(30 * 24 * 60 * 60); // 30 days
clickCookie.setSecure(true);
clickCookie.setHttpOnly(true);
clickCookie.setPath("/");
response.addCookie(clickCookie);
// Build destination URL with click ID appended for landing page correlation
String destination = appendClickId(shortUrl.getDestination(), clickId);
return ResponseEntity.status(HttpStatus.MOVED_PERMANENTLY)
.header("Location", destination)
.header("Cache-Control", "no-store")
.build();
}
private String appendClickId(String url, String clickId) {
String separator = url.contains("?") ? "&" : "?";
return url + separator + "_cid=" + clickId;
}The click ID appended to the destination URL is the durable anchor for first-party identity. Unlike UTM parameters, which are campaign metadata, this click ID ties back to a specific server-side record that you control. If the client-side analytics loses context through an in-app browser reset or a cross-domain session break, the click ID in the URL can still be read by the landing page and associated with the server-side record.
Layered Identity: Why Single Identifiers Always Fail
Attribution pipelines that depend on a single identifier — a GA4 client ID, a cookie, a device ID — will eventually encounter a failure scenario where that identifier is unavailable. In-app browsers don't share cookies with the system browser. Users clear storage. iOS 17's link tracking protection strips known tracking parameters. Cookie lifetimes are being reduced by browsers independently of regulatory requirements.
A resilient first-party pipeline uses layered identity — multiple identifier types, any one of which can anchor the attribution record when others are unavailable:
// Identity resolution: try deterministic identifiers first,
// fall back to probabilistic when necessary
@Service
public class IdentityResolutionService {
public String resolveUserId(HttpServletRequest request) {
// Layer 1: Authenticated user ID (strongest signal)
String authUserId = extractAuthenticatedUserId(request);
if (authUserId != null) return authUserId;
// Layer 2: First-party cookie set on previous visit
String cookieUserId = extractCookieUserId(request);
if (cookieUserId != null) return cookieUserId;
// Layer 3: Click ID from URL parameter (from short link redirect)
String clickId = request.getParameter("_cid");
if (clickId != null) {
// Look up user associated with this click ID
String linkedUserId = clickEventRepository.findUserByClickId(clickId);
if (linkedUserId != null) return linkedUserId;
}
// Layer 4: Probabilistic match (IP subnet + User-Agent hash)
// Use with caution — session-scoped only, never as durable identifier
String probabilisticId = buildProbabilisticId(request);
if (hasRecentMatch(probabilisticId)) return getProbabilisticMatch(probabilisticId);
// No match: new user
return null;
}
private String buildProbabilisticId(HttpServletRequest request) {
String ipSubnet = maskIp(request.getRemoteAddr());
String uaHash = hashUserAgent(request.getHeader("User-Agent"));
// Never store this as a persistent identifier
// Only use for same-session grouping
return DigestUtils.sha256Hex(ipSubnet + "|" + uaHash);
}
}The hierarchy matters: deterministic identifiers (authenticated user ID, first-party cookie) are used for durable attribution. Probabilistic matching is session-scoped only and explicitly not persisted as a long-term identifier. This distinction is both a privacy consideration and a data quality consideration — probabilistic IDs degrade in accuracy over time and across sessions in ways that corrupt historical attribution records if stored as if they were deterministic.
Server-Side Event Capture: Where Client-Side Tracking Fails
Client-side tracking has a fundamental problem for short-link attribution: the most important event — the click on the short link — happens before client-side JavaScript can execute. The redirect completes in milliseconds. A 301 response is followed before any script has loaded. By the time the destination page's analytics tag fires, the context from the originating click may have already been lost.
Server-side capture at the redirect handler is the only reliable way to record this event. The Spring Boot handler above handles this synchronously (or asynchronously if latency is a concern). For high-throughput scenarios, async persistence with a message queue between the redirect handler and the database prevents the database write from adding latency to the redirect response:
// High-throughput async event capture using Redis as a buffer
@Service
public class ClickEventService {
private final RedisTemplate<String, String> redisTemplate;
private final ObjectMapper objectMapper;
// Write to Redis queue immediately (sub-millisecond)
// Background worker persists to MariaDB asynchronously
public void recordAsync(ClickEvent event) {
try {
String json = objectMapper.writeValueAsString(event);
redisTemplate.opsForList().leftPush("click_events_queue", json);
} catch (JsonProcessingException e) {
// Fall back to synchronous write if serialization fails
log.error("Failed to serialize click event, writing synchronously", e);
clickEventRepository.save(event);
}
}
}
// Background worker — processes queue and writes to MariaDB
@Scheduled(fixedDelay = 100) // every 100ms
public void processClickEventQueue() {
List<String> batch = new ArrayList<>();
String item;
// Drain up to 500 events per cycle
while (batch.size() < 500 &&
(item = redisTemplate.opsForList().rightPop("click_events_queue")) != null) {
batch.add(item);
}
if (!batch.isEmpty()) {
List<ClickEvent> events = deserializeBatch(batch);
clickEventRepository.saveAll(events);
}
}This pattern keeps redirect latency under 2ms in most cases while ensuring events are eventually persisted to the primary database. The Redis queue also provides a buffer against database write spikes during campaign launches when click volume can be orders of magnitude higher than baseline.
Redirect Attribution Preservation
Redirects destroy attribution through four specific mechanisms, each of which requires a distinct mitigation:
Referrer stripping at HTTPS boundaries and by privacy-focused browsers. Safari and Firefox strip referrer headers by default in many cross-origin scenarios. Nginx configuration alone can't fix this — the mitigation is server-side capture at the redirect handler before the referrer has a chance to be stripped in transit.
UTM parameter loss in multi-hop redirect chains. Intermediate redirect handlers that don't explicitly forward query strings are a common source of UTM loss. Nginx requires explicit configuration:
# Nginx: preserve query string through redirect rules
# This applies when Nginx handles redirects directly (not proxied to Spring Boot)
# Wrong: drops query string, UTMs lost
location ~* ^/([a-zA-Z0-9_-]+)$ {
return 301 https://destination.com/page;
}
# Correct: preserves query string including UTMs
location ~* ^/([a-zA-Z0-9_-]+)$ {
return 301 https://destination.com/page?$query_string;
}
# For short URL service proxied to Spring Boot:
location ~* ^/([a-zA-Z0-9_-]+)$ {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# Prevent CDN from caching the redirect without query params
proxy_hide_header Cache-Control;
add_header Cache-Control "no-store, no-cache";
}Session fragmentation at cross-domain boundaries. When your short link domain (e.g., vvd.im) redirects to a landing page on a different domain, GA4 treats this as a new session by default. Cross-domain measurement must be explicitly configured in GA4, and the click ID appended to the destination URL provides an additional correlation mechanism that works even when GA4's cross-domain stitching fails.
In-app browser isolation. Links opened in WhatsApp, Telegram, LINE, or any app's built-in webview operate in an isolated browsing context. The webview doesn't share cookies with Safari or Chrome, and when the user later opens the destination in their main browser, it appears as a new user with no attribution history. The click ID appended to the URL survives this context switch — if the landing page reads the _cid parameter and associates it with the server-side click record, the attribution chain can be reconstructed even across browser context switches.
Journey Stitching: Connecting Fragmented Sessions
User journeys in 2025 are fragmented by default. A single conversion path commonly involves a first touch in an in-app browser, a return visit in the system browser two days later, and a final conversion on desktop. No single session contains the full picture.
First-party pipelines stitch these fragments through stable reference points — primarily the click ID and any authenticated user ID — rather than trying to maintain a continuous session. The stitching logic needs to handle three cases:
-- MariaDB schema for journey stitching
-- Separate click events from identity resolution to allow retroactive stitching
CREATE TABLE click_events (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
click_id VARCHAR(36) NOT NULL, -- UUID, set at redirect time
short_code VARCHAR(50) NOT NULL,
user_id VARCHAR(36), -- NULL if anonymous at click time
utm_source VARCHAR(200),
utm_medium VARCHAR(200),
utm_campaign VARCHAR(200),
referrer TEXT,
ip_subnet VARCHAR(20), -- /24 subnet, not full IP
user_agent_hash VARCHAR(64),
created_at TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(3),
INDEX idx_click_id (click_id),
INDEX idx_user_id (user_id),
INDEX idx_short_code_created (short_code, created_at)
) ENGINE=InnoDB;
CREATE TABLE identity_graph (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
canonical_user_id VARCHAR(36) NOT NULL, -- Your first-party user ID
identifier_type ENUM('auth', 'cookie', 'click_id', 'probabilistic') NOT NULL,
identifier_value VARCHAR(256) NOT NULL,
confidence TINYINT UNSIGNED NOT NULL, -- 100=deterministic, 1-99=probabilistic
first_seen TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(3),
last_seen TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(3),
UNIQUE KEY uk_type_value (identifier_type, identifier_value),
INDEX idx_canonical_user (canonical_user_id)
) ENGINE=InnoDB;
-- Retroactive stitching: when a user authenticates,
-- associate all prior click_ids from the same session with their user_id
UPDATE click_events ce
JOIN identity_graph ig ON ig.identifier_value = ce.click_id
AND ig.identifier_type = 'click_id'
SET ce.user_id = ig.canonical_user_id
WHERE ce.user_id IS NULL
AND ce.created_at > DATE_SUB(NOW(), INTERVAL 30 DAY);
The identity_graph table stores the mapping between all known identifiers and a canonical first-party user ID. When a user authenticates (logging in, subscribing), the application retroactively associates prior anonymous click IDs with the authenticated user ID. This retroactive stitching is what enables attribution for journeys where the user was anonymous at the time of the initial click but identified later at conversion.
Feeding First-Party Data Into GA4 Without Surrendering Control
GA4's Measurement Protocol allows server-side event submission, which is the right integration pattern for a first-party pipeline. Rather than relying on GA4's client-side tag to observe what it can, you send enriched events that include your first-party identifiers and pre-resolved attribution context:
// Server-side GA4 Measurement Protocol event submission
// Sends enriched attribution data using first-party identifiers
@Service
public class GA4MeasurementProtocolService {
private static final String GA4_ENDPOINT =
"https://www.google-analytics.com/mp/collect";
public void sendClickEvent(ClickEvent event, String ga4MeasurementId, String apiSecret) {
Map<String, Object> payload = Map.of(
"client_id", event.getClickId(), // Use first-party click ID as client_id
"timestamp_micros", event.getTimestamp().toEpochMilli() * 1000,
"events", List.of(Map.of(
"name", "short_link_click",
"params", Map.of(
"short_code", event.getShortCode(),
"campaign_source", event.getUtmSource(),
"campaign_medium", event.getUtmMedium(),
"campaign_name", event.getUtmCampaign(),
"first_party_click_id", event.getClickId(),
"session_id", event.getClickId() // anchor session to click
)
))
);
// Send asynchronously — don't block redirect for GA4 submission
webClient.post()
.uri(GA4_ENDPOINT + "?measurement_id=" + ga4MeasurementId
+ "&api_secret=" + apiSecret)
.bodyValue(payload)
.retrieve()
.bodyToMono(String.class)
.subscribe();
}
}The critical pattern here: GA4 is a consumer of data that your pipeline has already captured and stored. The GA4 Measurement Protocol call is supplementary — if it fails, the server-side click record is already persisted in your database. GA4's reporting is a view into your data, not the authoritative source of it. When GA4's numbers diverge from your server-side records (and they will), you have the ground truth to explain the discrepancy rather than arguing with a dashboard.
Handling Attribution Windows and Data Retention
Attribution models require a defined window — the maximum gap between a touchpoint and a conversion that still counts as attributable. GA4's default is 30 days for non-purchase conversions. For first-party pipelines, you define this yourself, which gives you more control but also requires explicit design:
-- Query: attribute conversions to click events within a 30-day window
-- using first-party click IDs for cross-session stitching
SELECT
ce.utm_source,
ce.utm_medium,
ce.utm_campaign,
COUNT(DISTINCT cv.conversion_id) AS conversions,
COUNT(DISTINCT ce.click_id) AS clicks,
ROUND(COUNT(DISTINCT cv.conversion_id) / COUNT(DISTINCT ce.click_id) * 100, 2)
AS conversion_rate_pct
FROM click_events ce
JOIN conversions cv
ON cv.user_id = ce.user_id
AND cv.converted_at BETWEEN ce.created_at
AND DATE_ADD(ce.created_at, INTERVAL 30 DAY)
WHERE ce.created_at >= DATE_SUB(NOW(), INTERVAL 90 DAY)
AND ce.utm_campaign IS NOT NULL
GROUP BY ce.utm_source, ce.utm_medium, ce.utm_campaign
ORDER BY conversions DESC;This query runs entirely against your first-party data — no GA4 API, no dependency on platform-managed identity. The attribution logic is transparent, auditable, and can be adjusted without waiting for a platform to change its model.
What Honest Attribution Actually Looks Like
A first-party attribution pipeline will produce numbers that are lower and more uncertain than what third-party tracking reported. That's not a failure — it's accuracy. Third-party tracking overstated certainty by filling gaps with inferred data that looked like real signal. First-party data exposes the gaps as gaps.
The operational benefit of this honesty: when data ends and assumptions begin, you know where the boundary is. Attribution decisions made with explicit uncertainty bounds are better than decisions made with false confidence in numbers that are quietly wrong.
The teams that get the most durable value from first-party attribution are the ones who stop trying to recover the inflated certainty of third-party tracking and instead build decision processes that work with explicitly bounded, honest data. That's the actual goal — not perfect attribution, but attribution you can explain and defend when the numbers are questioned.